안녕하세요 오늘은 인스타그램에서
좋아요와 해시태그를 크롤링해볼 겁니다.
매일 1일 1 개발하다 보니 힘드네요 암튼 시작!
1. 인스타그램 접속
셀레늄을 사용해서 제작해볼 겁니다
이번에는 제작한 프로그램의 코드를 공유해볼까 합니다
인스타그램에 접속해서 바로 html 코드를 분석해봅니다
셀레늄 이용방법에서 확인가능합니다
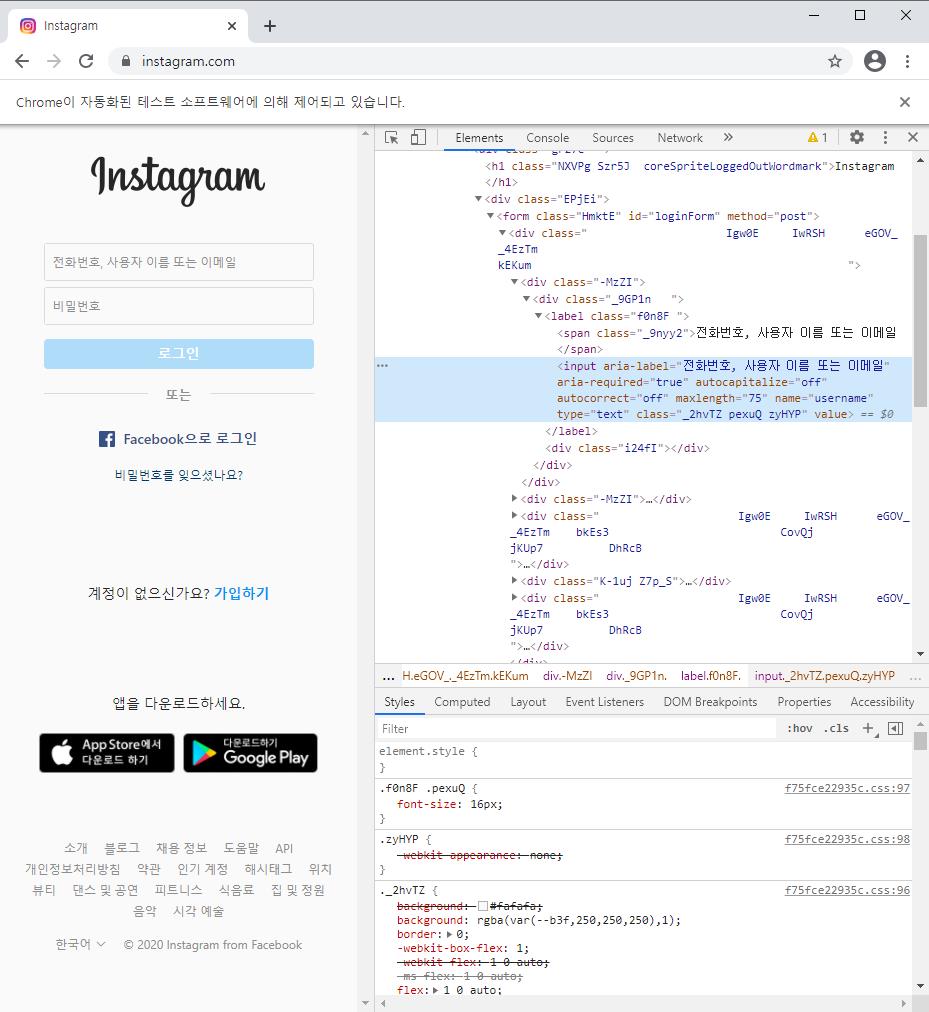
로그인을 하기 위해 아이디와 비밀번호 html코드를 분석해줍니다
driver.find_element_by_name('username').send_keys(vid)
driver.find_element_by_name('password').send_keys(vpw)
driver.find_element_by_xpath('//*[@id="loginForm"]/div/div[3]/button').click()로그인은 이렇게 하시면 됩니다
name을 이용해서 아이디와 비밀번호를 입력 후 로그인 버튼을 눌러주면 됩니다
로그인이 완료되었다면 입력한 키워드로 크롤링을 해보겠습니다
keyword = '음식'
driver.get('https://www.instagram.com/explore/tags/' + keyword)키워드를 사용해서 음식을 검색해줍니다
keyword는 input을 사용해서 원하는 키워드를 입력받아서 사용할 수도 있습니다.

인스타그램에 최근 사진 목록이 검색되었습니다
이 목록을 가져와 좋아요와 해시태그를 가져오면 됩니다
일단은 좋아요와 해시태그를 가져오기 위해서 첫 번째 사진을 클릭해서 게시글을 확인해봅시다

좋아요 html 코드 분석 결과 class명으로 선택해서 text로 빼내면 될 것 같습니다
진행방식은 class명 확인, 확인이 되었을 경우 페이지 코드를 가져오고,
beautifulsoup를 사용해서 좋아요를 가져오면 될것 같습니다
물론 driver에서도 find_element를 사용해서 text를 가져올 수 있으니
beautifulsoup를 사용하는 것이 많은 기능을 사용하면서 보여드릴 수 있는 기회라 생각돼서 사용하겠습니다
2. 좋아요 갯수 가져오기
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
driver.find_element_by_class_name('_9AhH0').click()
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "Nm9Fw")))
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
like = soup.select('.Nm9Fw')[0].text
print(like)좋아요를 가져오는 코드를 작성해봤습니다
driver.find_element_by_class_name('_9 AhH0'). click()
사진을 클릭해서 게시글을 확인합니다
WebDriverWait(driver, 5). until(EC.presence_of_element_located((By.CLASS_NAME, "Nm9 Fw")))좋아요 개수가 담긴 Class명이 Nm9 Fw이므로 5초 동안 Class명을 확인합니다
5초 이내에 Class명을 찾을 경우 반환합니다
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')좋아요가 화면에 표시된 것을 확인했으니 페이지 소스를 가져와 soup에 담아줍니다
like = soup.select('. Nm9Fw')[0].text수프에 담긴 페이지 소스에서 Nm9 Fw인 클래스명을 선택해 텍스트만 가져옵니다

좋아요를 크롤링해본 결과입니다
우리가 필요한 것은 숫자만 가져오는 것이기에 숫자만 추출을 해보도록 합니다
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
driver.find_element_by_class_name('_9AhH0').click()
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "Nm9Fw")))
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
like = soup.select('.Nm9Fw')[0].text
print(like)
like_num = re.sub('[^0-9]', '', like)
print(like_num)
좋아요 1,714개
1714이렇게 하면 원하는 값인 숫자만 추출했습니다
우리는 이제 검색 결과를 하나씩 둘러보며 크롤링해보면 됩니다

다음 게시글로 넘길 수 있는 버튼이 있어서 우리는 이 걸이 용하면 될 것 같다
항상 그랬듯 class명을 분석하거나 xpath를 가져오는 방법이 있는데
이번에는 class명이 너무 길어 xpath를 가져오기로 했다
for _ in range(10):
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div/a[2]').click()
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "Nm9Fw")))
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
like = soup.select('.Nm9Fw')[0].text
# print(like)
like_num = re.sub('[^0-9]', '', like)
print(like_num)딜레이를 안 줬더니 너무 빠르게 되었다

이렇게 테스트를 하던 도중 좋아요가 없는 게시글을 발견하게 되었다
우리는 다시 예외처리를 통해서 오류를 방지해야 프로그램의 중지를 막을 수 있다
for _ in range(10):
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div/a[2]').click()
try:
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "Nm9Fw")))
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
like = soup.select('.Nm9Fw')[0].text
# print(like)
like_num = re.sub('[^0-9]', '', like)
print(like_num)
except: pass정말 간단하게 예외처리를 해서 프로그램의 오류를 방지할 수 있을 것이다
3. 해시태그 가져오기
이제 우리는 해시태그를 가져오기면 하면 된다
해시태그의 특징을 살펴보면 #로 시작한다
#으로 시작하는 단어를 가져오면 될 것 같다
그전에 html 코드 분석을 통해 더 좋은 방법이 있는지 확인해보도록 한다

html 코드 분석 결과로는 해시태그는 xil3i라는 Class명을 가지고 있으며
href를 통해 바로 이동 가능하다
우리는 xil3i클래스명을 가져와서 for문을 돌리면 될듯하다
for _ in range(1):
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div/a[2]').click()
time.sleep(3)
try:
WebDriverWait(driver, 2).until(EC.presence_of_element_located((By.CLASS_NAME, "Nm9Fw")))
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
like = soup.select('.Nm9Fw')[0].text
vhashs = soup.select('..xil3i')
# print(like)
like_num = re.sub('[^0-9]', '', like)
print(like_num)
for li in vhashs:
vhash = li.text
print(vhash)
break
except: pass
5
#냥스타그램
#고양이
#집사그램
#집사
#캔따개
#나폴레옹
#일상
#daily
#cat
#🐱
#🐈
#❤️이렇게 우리는 해시태그까지 가져올 수 있었다
다음에 시간이 되면 크롤링한 결과를 모아 csv파일이나 pandas를 통해 정리를 해보도록 하겠다

'개발일지' 카테고리의 다른 글
| 네이버 검색어 세션 순서 크롤링 프로그램 개발일지 (1) | 2020.12.25 |
|---|---|
| 인스타그램 자동 좋아요 프로그램 개발일지 (0) | 2020.12.23 |
| 티스토리 쿠파스 자동 글쓰기 - 오쿠파스 개발일지 (1) | 2020.12.21 |
| 페이스북 자동 친구추가 프로그램 개발일지 [주문제작] (0) | 2020.12.20 |
| 네이버 서로이웃 자동 추가 프로그램 개발일지 (0) | 2020.12.19 |



